
初识Redis
引入
Nosql
基本概念
NoSQL最常见的解释是“non-relational”, “Not Only SQL”也被很多人接受。NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。
它不能替代关系型数据库,只能作为关系型数据库的一个良好补充。
优点:
- 易扩展
- 高性能
- 大数据量、高性能
- 高可用
Nosql 分类
不同分类特点对比:
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
基本概念
Redis 是一个使用c语言开发的高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
Redis 常被称作是一款数据结构服务器(data structure server)。Redis 的键值可以包括字符串(strings)类型,同时它还包括哈希(hashes)、列表(lists)、集合(sets)和 有序集合(sorted sets)等数据类型。
对于这些数据类型,你可以执行原子操作。例如:对字符串进行附加操作(append);递增哈希中的值;向列表中增加元素;计算集合的交集、并集与差集等。
Redis 的优点
- 性能极高:Redis 能支持超过 100K+ 每秒的读写频率。
- 丰富的数据类型:Redis 支持二进制案例的 Strings,Lists,Hashes,Sets 及 Ordered Sets 数据类型操作。
- 原子:Redis 的所有操作都是原子性的,同时 Redis 还支持对几个操作全并后的原子性执行。
- 丰富的特性:Redis 还支持 publish/subscribe,通知,key 过期等等特性。
下载及安装
下载地址
windows:
- Github下载地址:https://github.com/MicrosoftArchive/redis/releases
- 百度网盘下载地址:https://pan.baidu.com/s/1ziIEpSazWeAAH8HDUUwdgQ 提取码:
uvy2
安装步骤
首先先把下载的压缩包解压到一个文件夹中
打开cmd命令窗口
跳转到你刚才文件的解压路径,不会或者忘了的读者可以参考cmd操作
然后输入
redis-server redis.windows.conf命令接下来部署Redis为windows下的服务,首先关掉上一个窗口再打开一个新的cmd命令窗口。
同样进入redis的解压路径,然后输入指令
redis-server --service-install redis.windows.conf随后,进入右击此电脑–管理–服务和应用程序–服务 在服务列表中找到Redis 启动服务
测试redis,通过cd到我们解压的目录,输入指令通过Set get指令查看是否成功
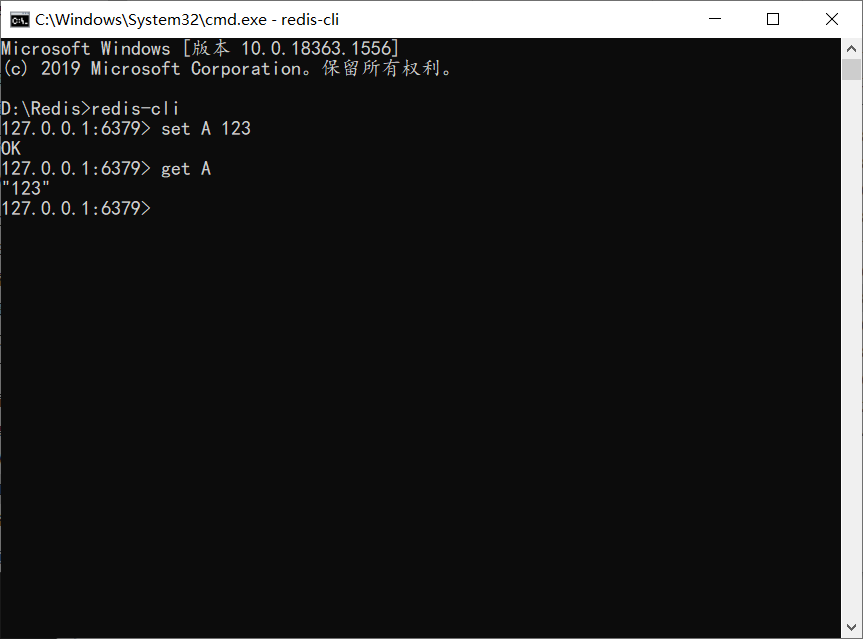
Redis常用的指令
卸载服务:redis-server --service-uninstall
开启服务:redis-server --service-start
停止服务:redis-server --service-stop
数据类型
String 类型
字符串是一种最基本、最常用的 Redis 值类型。
Redis 字符串是二进制安全的,这意味着一个 Redis 字符串能包含任意类型的数据
- 赋值 set key value
1 | set a 123 |
- 取值 get key
1 | get a |

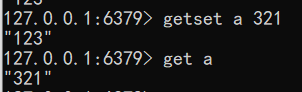
- 取值并赋值 getset key value
1 | getset a 321 |
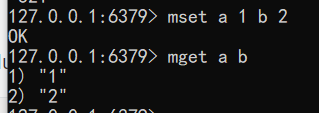
- 设置获取多个键值 mset key value [key value…] mget key [key…]
1 | mset a 1 b 2 |
- 删除 del key
1 | del a |

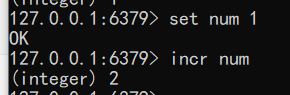
递增数字 当存储的字符串是整数时,Redis提供了一个实用的命令incr,其作用是让当前键值递增,并返回递增后的值。
语法:incr key
1
2set num 1
incr num
增加指定的整数 incrby key increment
1
incrby num 2
递减数值 decr key
1
decr num
减少指定的数值 decryby key decrement
1
decrby num 2



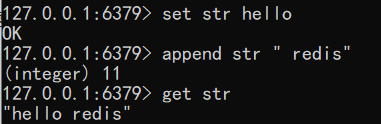
向尾部追加值 append的作用是向键值的末尾追加value。
如果键不存在则将该键的值设置为value,即相当于 SET key value。
返回值是追加后字符串的总长度。
语法:append key value
1 | set str hello |
获取字符串长度 STRLEN命令返回键值的长度,如果键不存在则返回0。
语法:strlen key
1 | strlen str |

List 类型
Redis的list是采用来链表来存储的,所以对于redis的list数据类型的操作,是操作list的两端数据来操作的。
命令
向列表两端增加元素
向列表前端增加元素
语法:lpush key value [value…]
1 | lpush list:1 1 2 3 |

向列表后面增加元素
语法:rpush key value [value…]
1 | rpush list:1 4 5 6 |

查看列表 LRANGE命令是列表类型最常用的命令之一,获取列表中的某一片段,将返回start、stop之间的所有元素(包含两端的元素),索引从0开始。索引可以是负数,如:“-1”代表最后边的一个元素。
语法:lrange key start stop
1 | lrange list:1 0 2 |

从列表两端弹出元素 LPOP命令从列表左边弹出一个元素,会分两步完成:
- 第一步是将列表左边的元素从列表中移除
第二步是返回被移除的元素值。
语法: lpop key rpop key
1
lpop list:1

获取列表中元素的个数
语法:llen key
1 | llen list:1 |

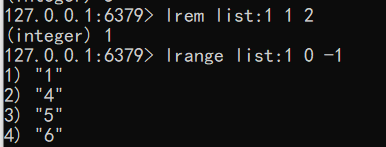
删除列表中指定的值 LREM命令会删除列表中前count个值为value的元素,返回实际删除的元素个数。根据count值的不同,该命令的执行方式会有所不同:
- 当count>0时, LREM会从列表左边开始删除。
- 当count<0时, LREM会从列表后边开始删除。
- 当count=0时, LREM删除所有值为value的元素。
语法:lrem key count value
1 | lrem list:1 1 2 |
获得/设置指定索引的元素值
获得指定索引的元素值
语法:lindex key index
1
lindex list:1 2
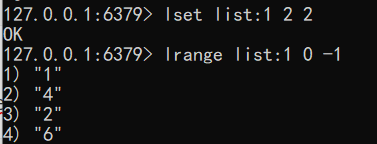
设置指定索引的元素值
语法:lset key index value
1
lset list:1 2 2
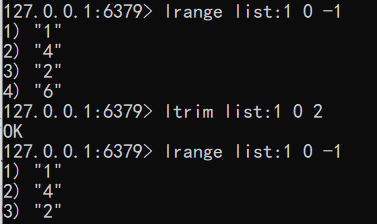
只保留列表指定片段 指定范围和 lrange 一致
语法:ltrim key start stop

1 | ltrim list:1 0 2 |
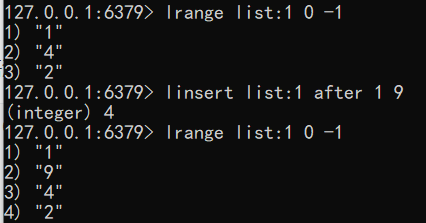
向列表中插入元素 该命令首先会在列表中从左到右查找值为pivot的元素,然后根据第二个参数是before还是after来决定将value插入到该元素的前面还是后面。
语法:linsert key before | after pivot value
1 | linsert list:1 after 1 9 |
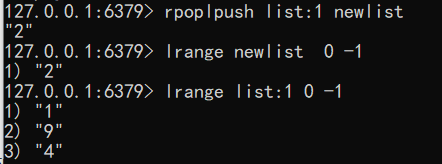
- 将元素从一个列表转移到另一个列表 语法:rpoplpush source destination
1 | rpoplpush list:1 newlist |
Hash 散列类型
使用 string 的问题
介绍
hash叫散列类型,它提供了字段和字段值的映射。字段值只能是字符串类型,不支持散列类型、集合类型等其它类型。如下:
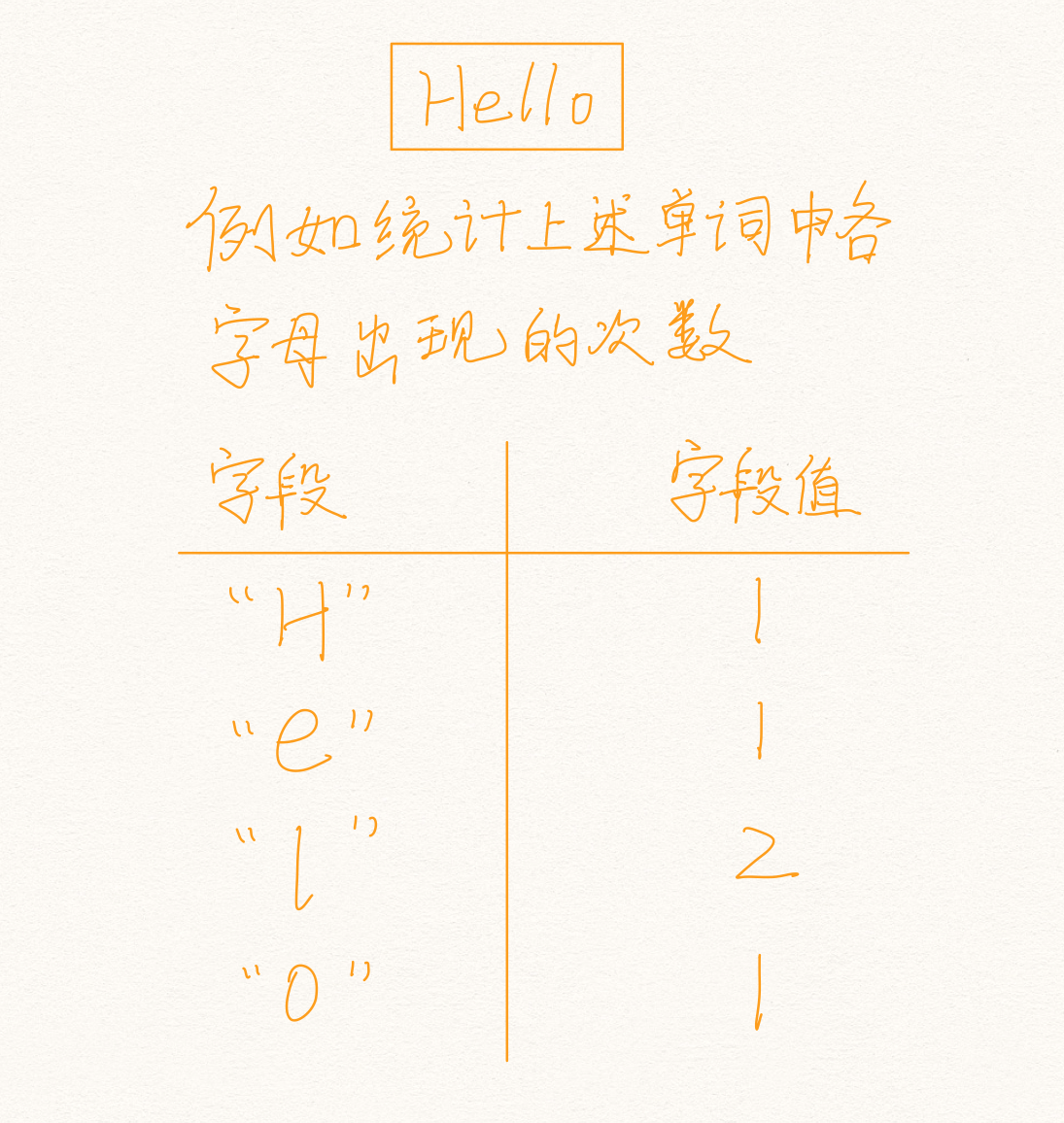
注意:图中字段是按字母出现顺序排序的,但是在散列存储中,是没有顺序的
命令
赋值 HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0。
- 一次只设置一个字段值 语法:hset key field value
1
hset dict H 1
- 一次设置多个字段值 语法:hmset key field value [field value…]
1
hmset dict e 1 l 2
- 当字段不存在时赋值,类似hset,区别在于如果字段存在,该命令不执行任何操作。 语法:hsetnx key field value
1
hsetnx dict o 1
取值
- 一次获取一个字段值 语法:hget key field
1
hget dict H
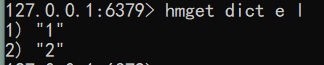
- 一次可以获取多个字段值 语法:hmget key field [field…]
1
hmget dict e l
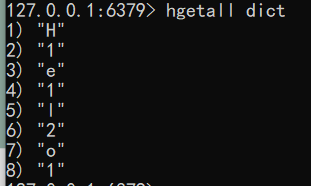
- 获取所有字段值 语法:hgetall key
1
hgetall dict
删除字段 可以删除一个或多个字段,返回值是被删除的字段的个数。
语法:hdel key field [field…]




1 | hdel dict H |

增加数字
语法:hincrby key field increment
1 | hincrby dict H 2 |

判断字段是否存在
语法:hexists key field
1 | hexists dict H |

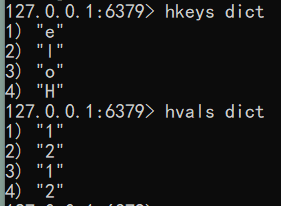
获取字段名
语法: hkeys key
获取字段值
语法: hvals key
1 | hkeys dict |
获取字段数量
语法:hlen key
1 | hlen dict |

Set 类型
集合(Set)类型:无序、不可重复
列表(List)类型:有序、可重复
命令
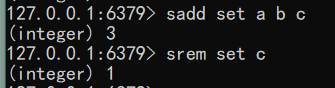
增加/删除元素
语法:sadd key member [member…]
1 | sadd set a b c |
语法:srem key member [member…]
1 | srem set c |
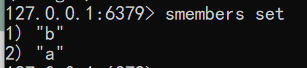
获得集合中的所有元素
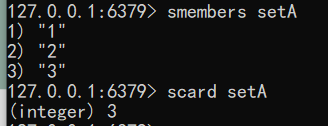
语法:smembers key
1 | smembers set |
判断元素是否在集合中
语法:sismember key member
1 | sismember set a |
运算命令
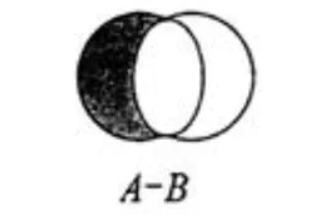
- 集合的差集运算 A-B 属于 A 并且 不属于 B 的元素构成的集合
语法:sdiff key [key…]
1 | sadd setA 1 2 3 |
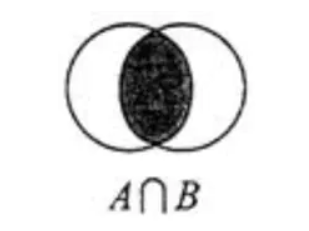
- 集合的交集运算 属于A且属于B的元素构成的集合
语法:sinter key [key…]
1 | sinter setA setB |

- 集合的并集运算 属于 A 或者 属于 B 的元素构成的集合

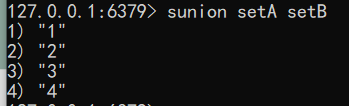
语法:sunion key [key…]
1 | sunion setA setB |
获得集合中元素的个数
语法:scard key
1 | scard setA |
从集合中弹出一个元素
注意:由于集合是无序的,所以spop命令会从集合中随机选择一个元素弹出。
语法:spop key
1 | spop setA |

Sortedset 类型
Sortedset 又叫 zset
Sortedset 是有序集合,可排序的,但是唯一。
Sortedset 和 set 的不同之处,会给 set 中元素添加一个分数,然后通过这个分数进行排序。
命令
增加元素
向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前已经存在的元素。
语法:zadd key score member [score member…]
1 | zadd scoreboard 80 zhangsan 89 lisi 94 wangwu |

获取元素分数
语法:zscore key member
1 | zscore scoreboard lisi |

删除元素
移除有序集key中的一个或多个成员,不存在的成员将被忽略。 当key存在但不是有序集类型时,返回一个错误。
语法:zrem key member [member…]
1 | zrem scoreboard lisi |

获得排名在某个范围的元素列表
按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素(包含两端的元素)
语法:zrange key start stop [withscores]
1
zrange scoreboard 0 2
按照元素分数从大到小的顺序返回索引从start到stop之间的所有元素(包含两端的元素)
语法:zrevrange key start stop [withscores]
1
zrevrange scoreboard 0 2
如果需要获得元素的分数可以在命令末尾加上 withscores 参数 ···
1
zrevrange scoreboard 0 2 withscores



获取元素的排名
从小到大
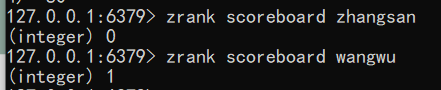
语法:zrank key member
1
2zrank scoreboard zhangsan
zrank scoreboard wangwu从大到小
语法:zrevrank key member
1
2zrevrank scoreboard zhangsan
zrevrank scoreboard wangwu

获得指定分数范围的元素
语法:zrangebyscore key min max [withscores] [limit offset count]
1 | zrangebyscore scoreboard 90 97 withscores |

增加某个元素的分数
返回值是更改后的分数
语法:zincrby key increment member
1 | zincrby scoreboard 4 lisi |

获得集合中元素的数量
语法:zcard key
1 | zcard scoreboard |

获得指定分数范围内的元素个数
语法:zcount key min max
1 | zcount scoreboard 80 90 |

按照排名范围删除元素
语法:zremrangebyrank key start stop
1 | zremrangebyrank scoreboard 0 1 |

按照分数范围删除元素
语法:zremrangebyscore key min max
1 | zadd scoreboard 84 zhangsan |

keys 命令
常用命令
keys 返回满足给定pattern 的所有key
1
keys list*
exists 确认一个key 是否存在
示例:从结果来看,数据库中不存在HongWan 这个key,但是A这个key 是存在的
1
2exists HongWan
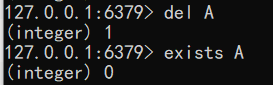
exists agedel 删除一个key
1
2del A
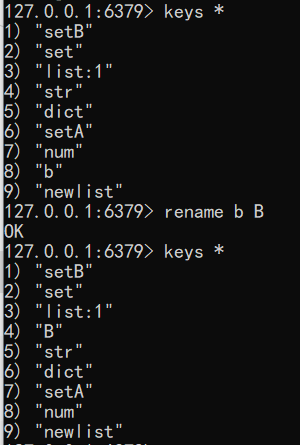
exists Arename 重命名key
示例:b成功的被我们改名为B了
1
2
3keys *
rename b B
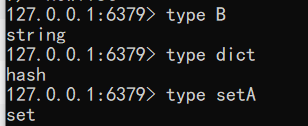
keys *type 返回值的类型
示例:这个方法可以非常简单的判断出值的类型
1
2
3type B
type dict
type setA


设置 key 的生存时间
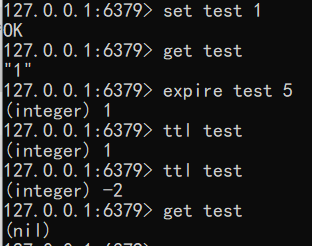
Redis在实际使用过程中更多的用作缓存,然而缓存的数据一般都是需要设置生存时间的,即:到期后数据销毁。
| EXPIRE key seconds | 设置key的生存时间(单位:秒)key在多少秒后会自动删除 |
| TTL key | 查看key剩余的生存时间 |
| PERSIST key | 清除生存时间 |
| PEXPIRE key milliseconds | 生存时间设置单位为:毫秒 |
例子:
1 | set test 1 |
Redis 持久化方案
Rdb 方式
Redis 默认的方式,redis 通过快照方式将数据持久化到磁盘中。
设置持久化快照的条件
在 Redis路径中的redis.conf(windows中是redis.windows.conf) 中修改持久化快照的条件:

将数据库保存在磁盘上:
#保存
#如果达到给定的秒数 和 给定的对数据库执行的写入操作数。
#在下面的示例中,将会进行保存操作:
#900秒(15分钟)后,至少有一个键更改
#300秒(5分钟)后,至少有10个键更改
#60秒后,至少10000个密钥发生更改
#注意:您可以通过注释掉所有“save”行来完全禁用保存。
#也可以删除以前配置的所有保存
#通过添加带有单个空字符串参数的save指令
#如以下示例所示:
#save“”
持久化文件的存储目录
在 redis.conf 中可以指定持久化文件的存储目录

#将数据库转储到的文件名
dbfilename dump.rdb
#工作目录
#DB将被写入这个目录,使用上面使用’dbfilename’配置指令指定的文件名。
#只附加的文件也将在这个目录中创建。
#请注意,必须在此处指定目录,而不是文件名。
dir ./
Rdb 的问题
一旦redis非法关闭,那么会丢失最后一次持久化之后的数据。
如果数据不重要,则不必要关心。 如果数据不能允许丢失,那么要使用 aof 方式。
Aof 方式
Redis 默认是不使用该方式持久化的。Aof 方式的持久化,是操作一次 redis 数据库,则将操作的记录存储到 aof 持久化文件中。
第一步:开启 aof 方式持久化方案。 将redis.conf中的appendonly改为yes,即开启aof方式的持久化方案。
Aof文件存储的目录和rdb方式的一样。 Aof文件存储的名称
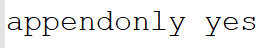

#默认情况下,Redis将数据集异步转储到磁盘上。
#此模式在许多应用程序中已经足够好了,
#但是Redis进程或断电可能会导致几分钟的写操作丢失(取决于配置的保存点)。
#仅附加文件是一种提供更好的耐用性。
#例如,使用默认数据fsync策略(请参阅后面的配置文件)
#Redis在一段时间内只会丢失一次的写操作
#某些戏剧性的事件,
#比如服务器断电,或者某个事件发生时的一次写入导致Redis进程本身出错,但操作系统仍然正常运行。
#AOF和RDB持久性可以同时启用而不会出现问题。
#如果启动时启用了AOF,Redis将加载AOF,
#即文件具有更好的耐久性保证。
appendonly yes
#仅附加文件的名称(默认值:“appendonly.aof”)
appendfilename“appendonly.aof”
在同时使用aof和rdb方式时,如果redis重启,则数据从aof文件加载。
总结
这次的《初识Redis》就写到这里了,笔者在写这篇文章中也收获良多,本次部分学习来源:实验楼《Redis 简明教程》,掘金社区轻云时解的《Redis 入门》,Redis官网教程文档。



